29 Mar 2026
Google’s TurboQuant work is worth paying attention to, but not for the usual “AI just changed everything” reasons.
Why this matters
In recent posts, I’ve talked about tokens, vectors, and context windows, and how they shape the way LLMs work. TurboQuant sits right at the intersection of all three.
The idea is actually pretty simple.
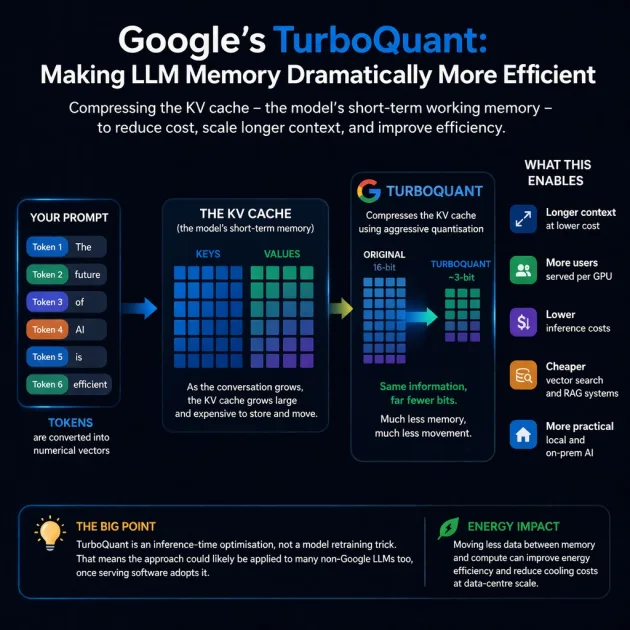
When you type a prompt, the model doesn’t just read it once. It stores a numerical representation of what you typed as tokens in a Key-Value (KV) cache. That acts as the model’s short-term working memory.
As context grows, that cache grows too, and the cost of storing and moving it becomes a serious bottleneck.
TurboQuant is about compressing that memory much more aggressively while largely preserving model performance.
What TurboQuant is not
This is not “quantum” computing.
It is about quantisation. In other words, it is about storing the model’s working data using fewer bits.
The real story is not “quantum AI”. It is that Google may have found a clever way to achieve extreme compression without wrecking results.
Why it could matter
If this holds up outside Google’s own benchmarks, the implications are pretty significant:
- Longer context becomes cheaper
- More users can be served per GPU
- Inference costs could drop
- Vector search and RAG systems could get cheaper too
- Local and on-prem AI become more realistic and affordable
The most interesting part is that this does not seem to be a Google-only idea.
Because it is an inference-time optimisation rather than a model-specific retraining trick, the same general approach could likely be applied to many non-Google LLMs as well, assuming the serving software catches up.
A useful benchmark
A good test of a compression algorithm is the Needle-in-a-Haystack benchmark, which evaluates whether an AI can find a single specific sentence hidden within 100,000 words, or roughly 130,000 tokens.
In testing across open-source models such as Llama-3.1-8B and Mistral-7B, TurboQuant achieved perfect recall scores, matching the performance of uncompressed models while reducing the KV cache memory footprint by at least 6x.
The bigger picture
Because it reduces the amount of data that needs to be moved around during inference, it could also improve energy efficiency.
At data-centre scale, even modest gains there matter for both electricity and cooling.